开始
前几天使用数据恢复软件恢复了一批word文档(大概2k个),但是有些文档已经被损坏了,完全打不开。
用word修复工具能修复吗?抱着这样的想法尝试了市面上大部分的修复工具。
结果都修复失败。
这个时候尝试看看原始数据?
用一款开源的软件imhex
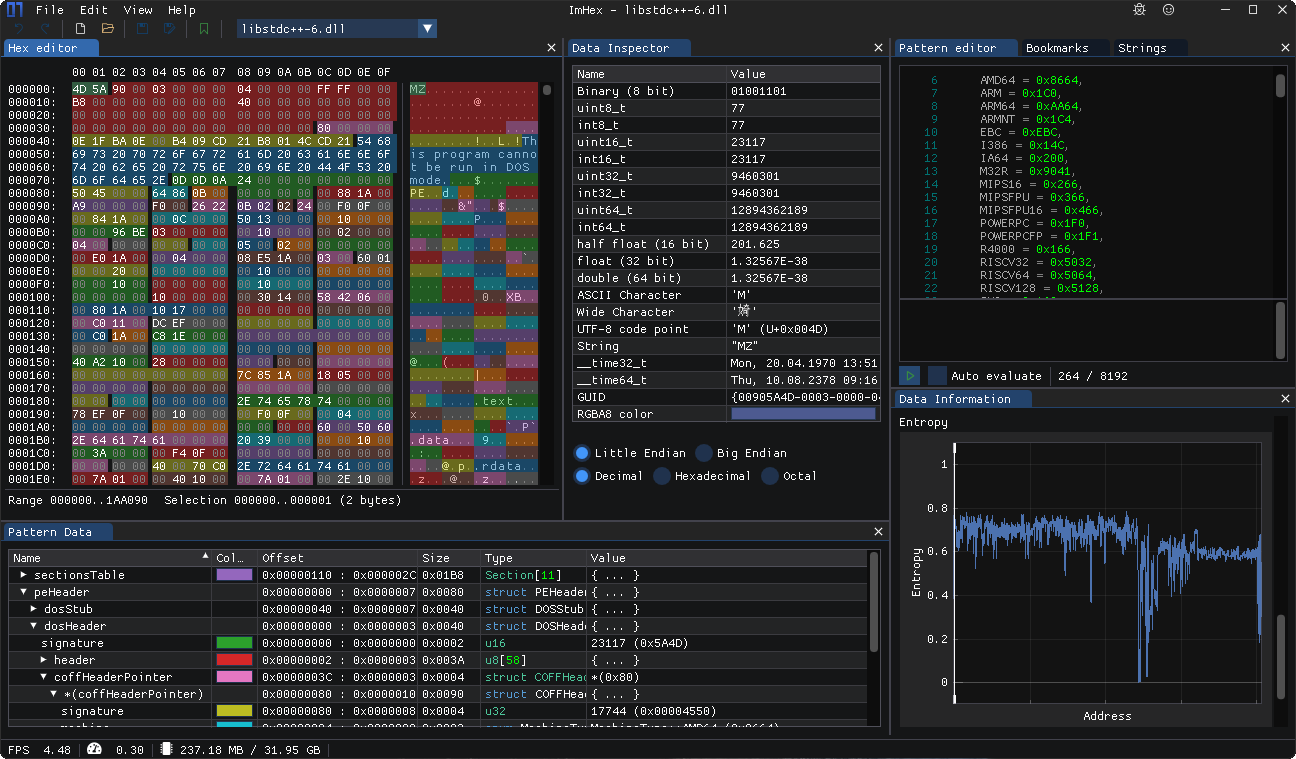
直接查看这些文档的16进制数据。
![Alt text]
好好好,就剩个文件路径了是吧。损坏成这样只有神笔马良能修复了。
这种文件已经不可能修复了。不过剩下的几百个文件是否还有完好无损的呢?
希望

这种文件大小还挺大,或许还有希望恢复。
但打开后还是有些乱码有些正常。
按照大小筛选一下后发现还是有几百个文档,有没有更高效的办法查看一个文档是否损坏呢?
小知识
office里的word,ppt以及xls文件本质上都是一个zip压缩包。
它们的资源都保存在这个压缩包里。
例如这里有一个ppt幻灯片,里面有一张图片。
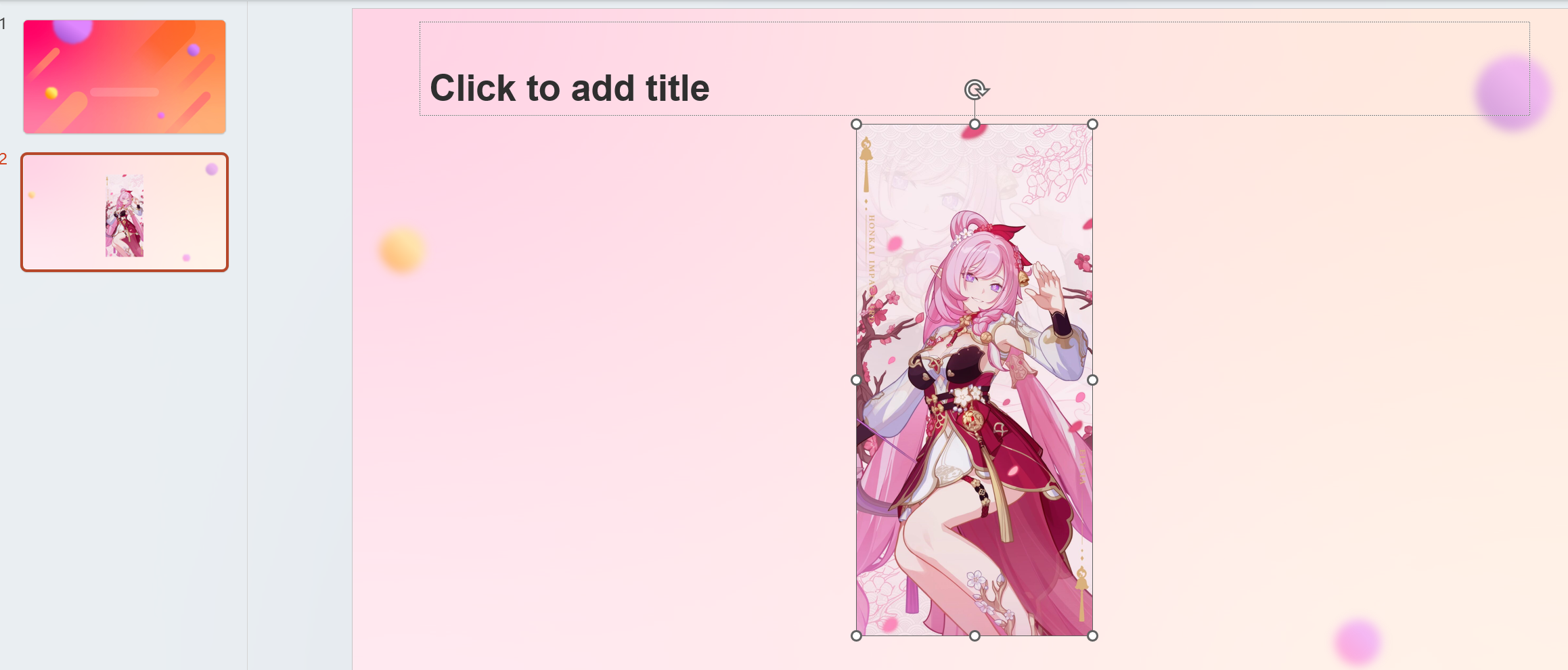
把它的后缀名改为.zip后解压,会得到一个这样的目录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| │ [Content_Types].xml
│
├─docProps
│ app.xml
│ core.xml
│ custom.xml
│ thumbnail.jpeg
│
├─ppt
│ │ presentation.xml
│ │ presProps.xml
│ │ tableStyles.xml
│ │ viewProps.xml
│ │
│ ├─media
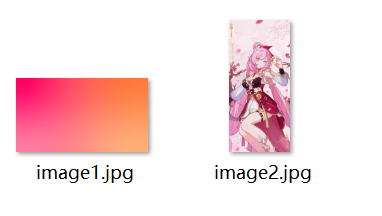
│ │ image1.jpg
│ │ image2.jpg
│ │
│ ├─slideLayouts
│ │ │ slideLayout1.xml
│ │ │ slideLayout2.xml
...
|
其中media文件夹里的image.jpg就是幻灯片插入的图片。
所以根据这个特点,通过对几个文件的观察。
会发现正常文件和损坏文件解压后的文件树都发生了变化。
其中word\document.xml这个文件最为关键。如果这个文件不存在的话,那么就无法正常打开,可以认定为是损坏文档。
但是有的文档有word\document.xml文件,但解压的话就会出现错误。
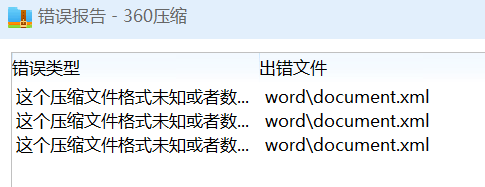
这时就不能单纯根据文件的有无来下判断了,还需要尝试解压一下。
工具
这种小脚本就到了Python上场了,多轮子可以直接调用。
需要的模块
os。用于读取文件。zipfile。解压文件。shutil。将正常文档放到一个文件夹保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import os
import zipfile
import shutil
def extract_and_copy_files(directory_path, output_folder):
try:
for file_name in os.listdir(directory_path):
file_path = os.path.join(directory_path, file_name)
if os.path.isfile(file_path):
try:
with zipfile.ZipFile(file_path) as zip_file:
for zip_file_name in zip_file.namelist():
if zip_file_name == "word/document.xml":
extract_folder = os.path.join(directory_path, "temp")
zip_file.extractall(extract_folder)
extracted_file_path = os.path.join(
extract_folder, zip_file_name
)
if os.path.isfile(extracted_file_path):
print("找到正常文档:", file_name, "\n正在复制")
if not os.path.exists(output_folder):
os.makedirs(output_folder)
output_file_path = os.path.join(
output_folder, file_name
)
shutil.copy2(file_path, output_file_path)
shutil.rmtree(extract_folder)
except zipfile.BadZipFile:
print(f"{file_name}已损坏")
except:
print(f"文件{zip_file_name}解压失败")
except FileNotFoundError:
print(f"错误: 目录 '{directory_path}' 未找到")
except Exception as e:
print(f"发生错误: {e}")
directory_path = "..."
output_folder = os.path.join(directory_path, "good")
extract_and_copy_files(directory_path, output_folder)
|
小结
看着控制台飞速滚动,2k个文档几秒内就全部整理完了(最后只有28个正常打开)。
如果手动一个个点开看的话不知道要多久。
感慨这种重复机械的工作还是计算机擅长。
利用自己的知识,以超高的效率解决问题,这可能就是编程的魅力所在吧。


